
Language Detection using N-Grams - Part II
 In our previous post we have described the general process of training an N-Gram language detector. If you have not yet read the post describing the general technique I suggest that you have a look at that first. In this post we will go through the implementation details and creation of a simple language detector using Node. To keep this post concise I will set the language detection parameters - top n-grams to select and n-gram length - manually. In a future post I will show you how to optimise the selection of these parameters by splitting the dataset into three parts; training, validation and test.
In our previous post we have described the general process of training an N-Gram language detector. If you have not yet read the post describing the general technique I suggest that you have a look at that first. In this post we will go through the implementation details and creation of a simple language detector using Node. To keep this post concise I will set the language detection parameters - top n-grams to select and n-gram length - manually. In a future post I will show you how to optimise the selection of these parameters by splitting the dataset into three parts; training, validation and test.
Language Profiles
One of the most important parts of an N-Gram language detector is the creation of language profiles. For this we need some sample text in each language we want to detect. There are many datasets out there which can be used for this purpose, but for this post we will use the Universal Declaration of Human Rights Database since i) it has been translated into over 460 different languages and dialects and ii) it’s free.
One question you might have is whether the source dataset choice affects the quality of our detector. If you remember well from the previous post, the N-Gram distribution for the top 300 or so N-Grams are always highly correlated to the language. It is only when we start making use of more N-Grams that our source document choice will become important since it will start skewing the NGram distribution and make it topical.
Having justified our dataset choice, go ahead and download the declaration of human rights PDF for each language you are interested in from here and covert these PDFs to text. Feel free to use my language subset if you want to get started immediately. This dataset includes the following languages:
- czc.txt - Czech (Cesky)
- dns.txt - Danish (Dansk)
- dut.txt - Dutch (Nederlands)
- eng.txt - English
- frn.txt - French (Français)
- ger.txt - German (Deutsch)
- grk.txt - Ellinika’ (Greek)
- hng.txt - Hungarian
- itn.txt - Italian
- jpn.txt - Japanese (Nihongo)
- lat.txt - Latvian
- lit.txt - Lithuanian (Lietuviskai)
- ltn.txt - Latin (Latina)
- ltn1.txt - Latin (Latina)
- lux.txt - Luxembourgish (Lëtzebuergeusch)
- mls.txt - Maltese
- por.txt - Portuguese
- rmn1.txt - Romani
- rum.txt - Romanian (Româna)
- rus.txt - Russian (Russky)
- spn.txt - Español (Spanish)
- ukr.txt - Ukrainian (Ukrayins’ka)
- yps.txt - Yapese
Now that we have a sample textfile for each language let us create the language profiles using Node. First let’s create a package.json similar to the following:
{
"name": "language-detector",
"version": "1.0.0",
"description": "Language Detector Using NGrams",
"main": "train.js",
"author": "Mark Galea",
"scripts": {
"train": "./train.js",
},
"dependencies": {
"glob": "^7.0.3"
}
}
and run npm install to install the required dependencies. Note the scripts sections contains a train command which will invoke the ./train.js javascript file.
After downloading and installing all the dependencies, let us create the function generateProfile which will create an NGram profile. Since the language profiles and document profile are generated using the same process we will extract this common functionality in the file ngram-utils.js.
function sortNgrams(ngrams){
return Object.keys(ngrams).map(function(key) {
return {'ngram': key, 'freq':ngrams[key]};
}).sort(function(first, second) {
// If the frequency is the same favour larger ngrams
return second['freq'] - first['freq'];
}).map(function(ngram, index){
ngram['index'] = index;
return ngram;
});
}
function merge(obj1,obj2){
var obj3 = {};
for (var attrname in obj1) { obj3[attrname] = obj1[attrname]; }
for (var attrname in obj2) { obj3[attrname] = obj2[attrname]; }
return obj3;
}
function getNgrams(text, n){
var ngrams = {};
var content = text
// Make sure that there is letter a period.
.replace(/\.\s*/g, '_')
// Discard all digits.
.replace(/[0-9]/g, "")
//Discard all punctuation except for Apostrophe.
.replace(/[&\/\\#,+()$~%.":*?<>{}]/g,'')
// Remove duplicate spaces.
.replace(/\s*/g, '')
.toLowerCase();
for(var i = 0; i < content.length - (n-1); i++){
var token = content.substring(i, i + n);
if (token in ngrams)
ngrams[token] += 1;
else
ngrams[token] = 1;
}
return ngrams;
}
exports.generateProfile = function(text, topN){
var biGrams = getNgrams(text, 2);
var triGrams = getNgrams(text, 3);
var ngrams = merge(biGrams, triGrams);
var sortedNgrams = sortNgrams(ngrams);
return sortedNgrams.slice(0, topN);
}
The code is pretty self explanatory:
- The
getNgramsfunction takes in an input stringtexttogether with thenGramlength and returns a list of nGrams frequencies. - The
sortNgramsfunction takes in a dictionary of nGrams and sorts them by frequency storing theindex. - The
generateProfilecombines the functionality provided by these two methods in order to merge a list of bi-grams and tri-grams returning the topNresult based on frequency.
Finally, let us create a language profile for each language present in the subset folder and save all profiles in the file language-profile.json. We will make use of this profile file in the next section.
#!/usr/bin/env node
var glob = require("glob")
var fs = require('fs');
var ngramUtils = require('./ngram-utils');
var ngrams = {}
console.log("Started Application");
// options is optional
glob("subset/*.txt", function (er, files) {
var languageProfile = {};
files.forEach(function(file){
var lang = path.basename(file, '.txt');
console.log("Training [Lanugage: ", lang, "] [File: ", file, "]");
var text = fs.readFileSync(file,'utf8');
languageProfile[lang] = ngramUtils.generateProfile(text, 300);
});
fs.writeFileSync('language-profile.json', JSON.stringify(languageProfile));
console.log("Written Language Profile to File [language-profile.json]");
});
Detection
Now that we have created our language profiles, how can we use these profiles to detect the language of a text fragment?
What we need to do is to use the generateProfile function to create a document profile and use this document profile to calculate a simple rank-order statistic which we will call the “out of place” measure.
Before we continue, let’s expose the detect command in the package.json - so that we can invoke detection using npm run detect <phrase> - and create the initial detect.js file:
{
"name": "language-detector",
"version": "1.0.0",
"description": "Language Detector Using NGrams",
"main": "train.js",
"author": "Mark Galea",
"scripts": {
"train": "./train.js",
"detect": "./detect.js"
},
"dependencies": {
"glob": "^7.0.3"
}
#!/usr/bin/env node
var fs = require('fs');
var ngramUtils = require('./ngram-utils');
Now let us read the language profiles we have created in the previous step.
console.log("Reading Language Profiles from [language-profile.json]");
var languageProfiles = JSON.parse(fs.readFileSync('language-profile.json', 'utf-8'));
Next, let us read the user text fragment and generate the document profile.
var text = process.argv[2];
console.log("Determining Language for [text: ", text, "]");
var documentProfile = ngramUtils.generateProfile(text, 300);
Now it’s time to compute the “out of place” measure for each NGram present in the document profile.
documentProfile.forEach(function(documentNgram){
var documentIndex = documentNgram.index;
var languages = Object.keys(languageProfiles);
languages.forEach(function(language){
var languageProfile = languageProfiles[language];
var languageNgram = languageProfile.filter(function(languageNgram){
return languageNgram.ngram == documentNgram.ngram;
});
if (languageNgram.length == 1){
// We found the ngram so we compute the out of place measure.
scores[language] += Math.abs(languageNgram[0].index - documentIndex);
} else {
// We did not find the ngram so we penalise.
scores[language] += NOT_FOUND;
}
});
});
Finally, let us sort the score results and present them to the user. Note that the lower the score the “closer” the text fragment is to the language.
function sortScores(scores){
return Object.keys(scores).map(function(language) {
return {'language': language, 'score':scores[language]};
}).sort(function(first, second) {
return first['score'] - second['score'];
});
}
console.log(JSON.stringify(sortedScores));
Source Code
If you are having trouble with the implementation I have uploaded the complete source code on Github. Once you cloned the repository run npm install and create the language profiles by executing:
npm run train
You can try the detector by executing:
npm run detect <phrase>
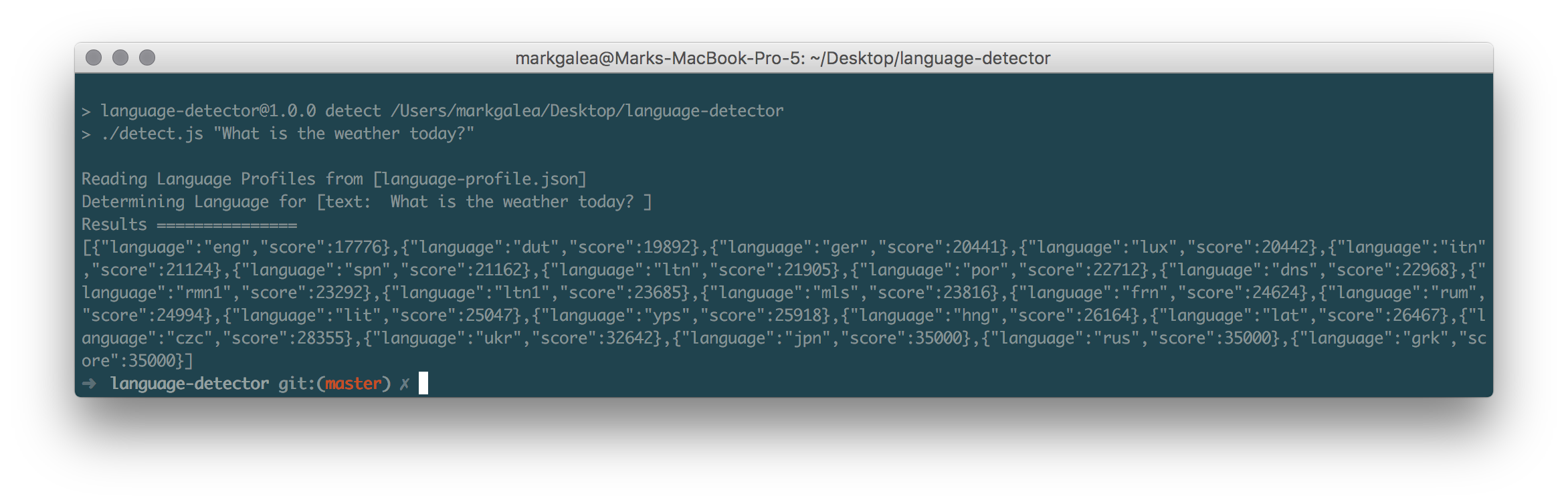
As an example, running the detector with the phrase “What is the weather today?” will detect that the phrase is in English.
npm run detect "What is the weather today?"
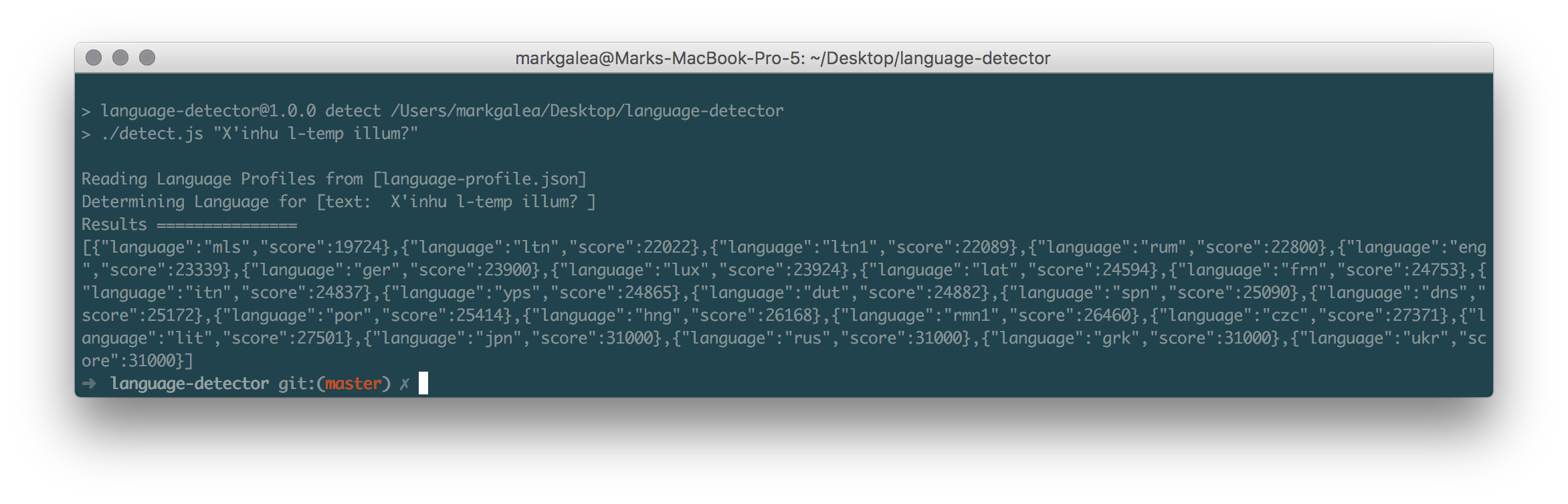
Running the detector on the same phrase translated to Maltese will detect that the phrase is in Maltese
npm run detect "X'inhu t-temp illum?"
Conclusion
In this post we have implemented an NGram language detector using Node. Hope you guys had fun reading this post! Stay safe and keep hacking!