
Node Management in GKE
 It’s been one heck of a week! I’m back from the Google Cloud Summit in Milan - #GoogleCloudSummit - where Mattia (@mattiagnd) and I spoke about Node management in GKE. In this blog I would like to take some points discussed in that presentation and really outline some key takeaways; specifically what happens during an upgrade and what steps we (as clients of GKE) can take in order to manage disruptions.
It’s been one heck of a week! I’m back from the Google Cloud Summit in Milan - #GoogleCloudSummit - where Mattia (@mattiagnd) and I spoke about Node management in GKE. In this blog I would like to take some points discussed in that presentation and really outline some key takeaways; specifically what happens during an upgrade and what steps we (as clients of GKE) can take in order to manage disruptions.
Managing the fleet - GKE Upgrades
One thing I’m really proud of at Suprnation is the fact that for the past three years we had very few crashes. Even more impressive is the fact that our systems auto-recovered from such crashes. Such an outcome is the result of an earlier decision to go reactive - see the reactive manifesto - and the “let it crash” philosophy ingrained throughout our system.
Reactive Systems are typically composed of smaller components which cooperate together to achieve a common goal. Deploying these small components is challenging; how do we isolate, schedule, configure and supervise these components? This is where Kubernetes comes in; it addresses all of these issues. Specifically we use Google Kubernetes Engine, the hosted Kubernetes engine offered by Google.
When using Kubernetes, systems administrators can focus on managing the fleet rather than manage individual components. One challenging aspect of managing a fleet is upgrades. On one hand upgrades give us access to the latest features, but on the other hand they disrupt our business. So what goes on during an upgrade? Well let’s visualise the upgrade sequence.
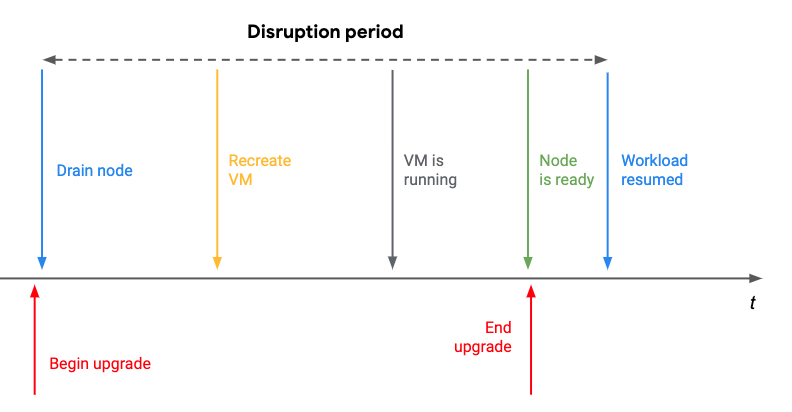
Node by node, each node is drained, a new VM is created and GKE will wait for the VM to start running. Once running, GKE will register the node with the master and become ready. Once ready, the workload is resumed. During this period - disruption period - your business might (and probably will) experience disruptions.
Can we do better? One feature which is coming up in the next release for GKE is surge-upgrades. If we look at the previous disruption period we can see that certain things can be moved out. Specifically, an extra VM - called a surge VM - can be created before draining the node. By creating an extra VM in this manner we can see that the disruption period shortens and is equal to the time it requires Kubernetes to reschedule your workload from node-to-node. Visually this looks as follows
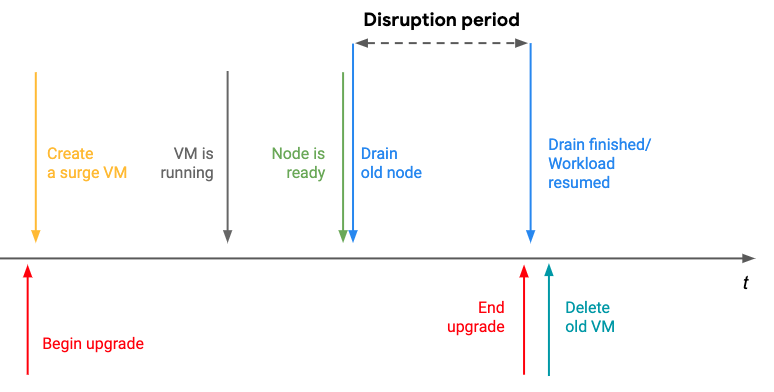
Surge upgrades will really help us reduce disruptions faced by our clients but this is not a silver bullet. There is only so much magic Google can do in order to make sure that our applications are reliable. There are things which we can ourselves in order to protect ourselves against disruptions. So what are disruptions?
Workload Disruptions
Let’s create a simple application and deploy this on a cluster in order to understand better what workload disruptions are.
const http = require('http');
const os = require('os');
var handler = function(request, response) {
console.log("Received request from " + request.connection.remoteAddress);
response.writeHead(200);
response.end("Hit " + os.hostname() + "\n");
};
http.createServer(handler).listen(8080);
As you can see from the code at the top we are creating a simple server which responds to a client request. We package this application, deploy it on a three-node cluster and expose it via a service by using the following commands
> kubectl run platform --labels="app=platform" --image=platform:v1 --port=8080
> kubectl expose deployment platform --type=LoadBalancer --port=8080 --name platform-http
Visually, this is what we have achieved
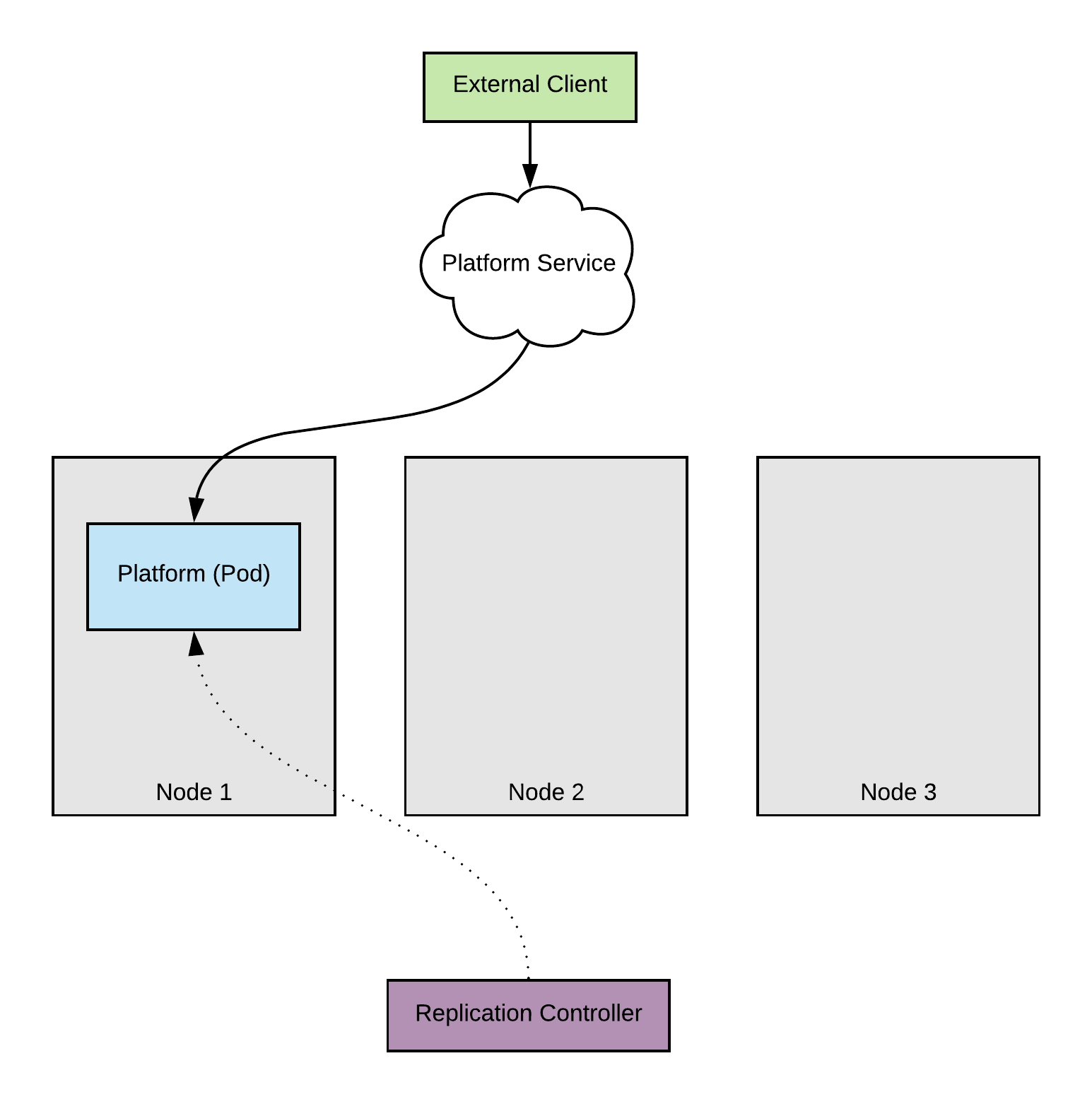
So what’s happening here? The client will hit the HTTP endpoint and the service will forward the request to one of the available pods to get serviced. If no pods are available the client will fail to connect.
So let’s run an upgrade scenario. As we mentioned previously, during an upgrade a node is taken down and all pods running on that node are evicted. What this means is that our application will start throwing errors since the pod is evicted but requests are still hitting the endpoint. Of course Kubernetes reschedules the pod and the situation recovers but there is this inevitable period where our application will surely serve errors if hit. Visually this scenario looks as follows
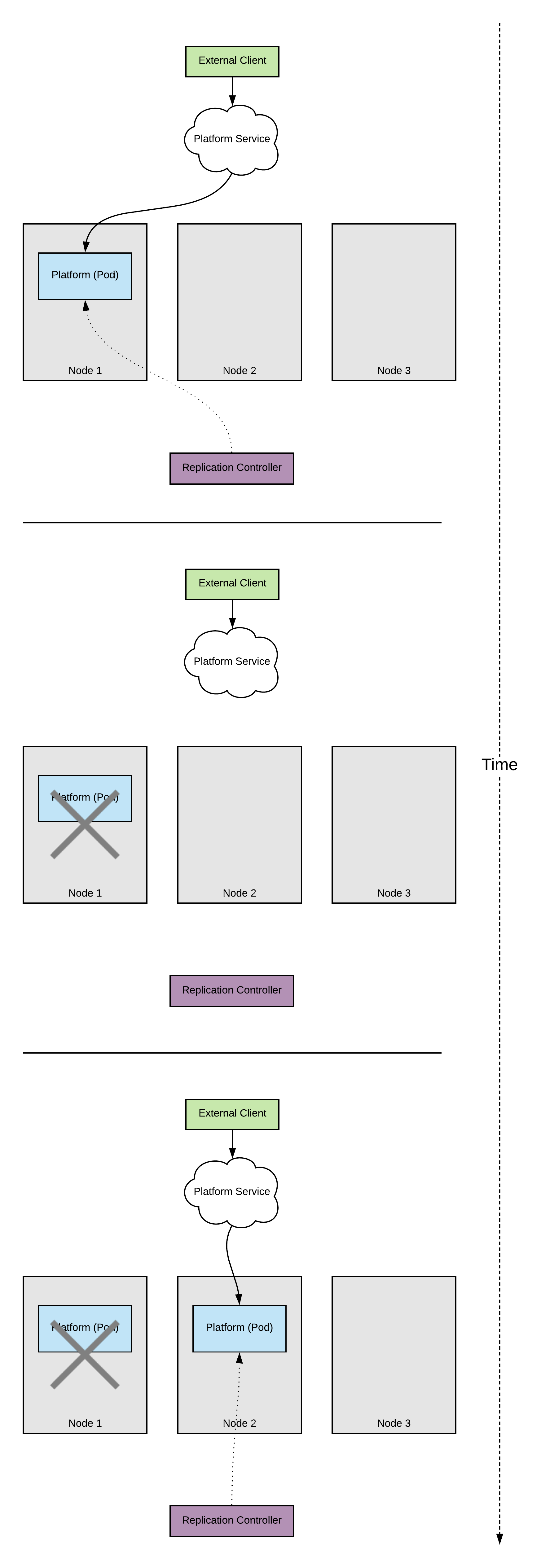
Replicas
So what can we do to mitigate this situation? One obvious thing to do here is to increase the number of replicas that we have. Let’s update the deployment to scale up to 3 replicas.
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
app: platform
name: platform
spec:
replicas: 3
selector:
matchLabels:
app: platform
template:
spec:
containers:
- image: platform:v1
name: platform
ports:
- containerPort: 8080
protocol: TCP
Alternatively we can use the command
> kubectl scale deployment platform --replicas=3
Immediately we have three pods scheduled and running. One important question to ask here is but Where are these pods running? In this case we can see that we have one pod running on node 1 and two pods running on node 2. Let’s really digest what this means in an upgrade scenario.
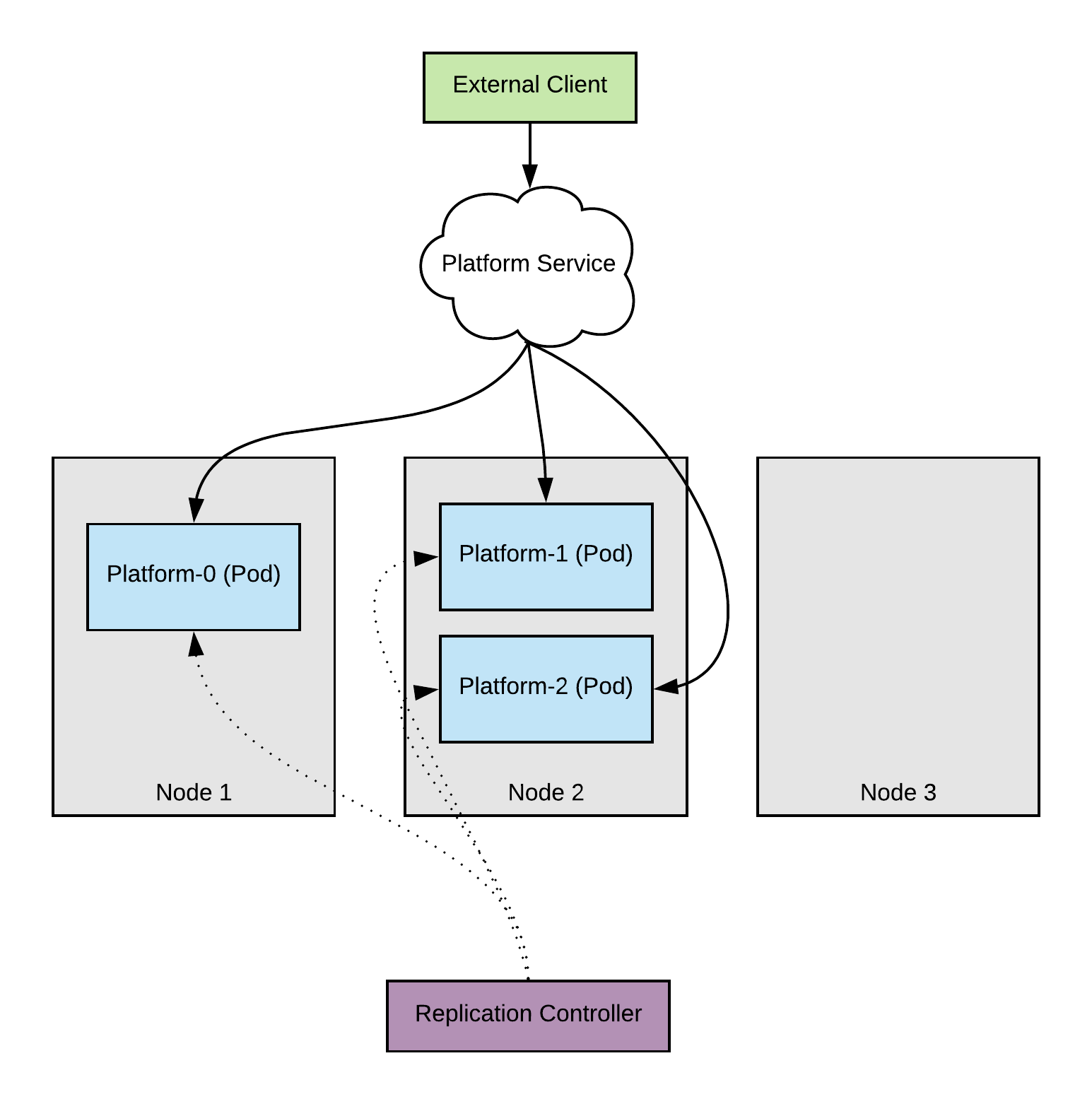
When node 1 is upgrading, the pod is evicted. In contrast to what we had before our clients are still being serviced since we have 2/3 of our capacity available.
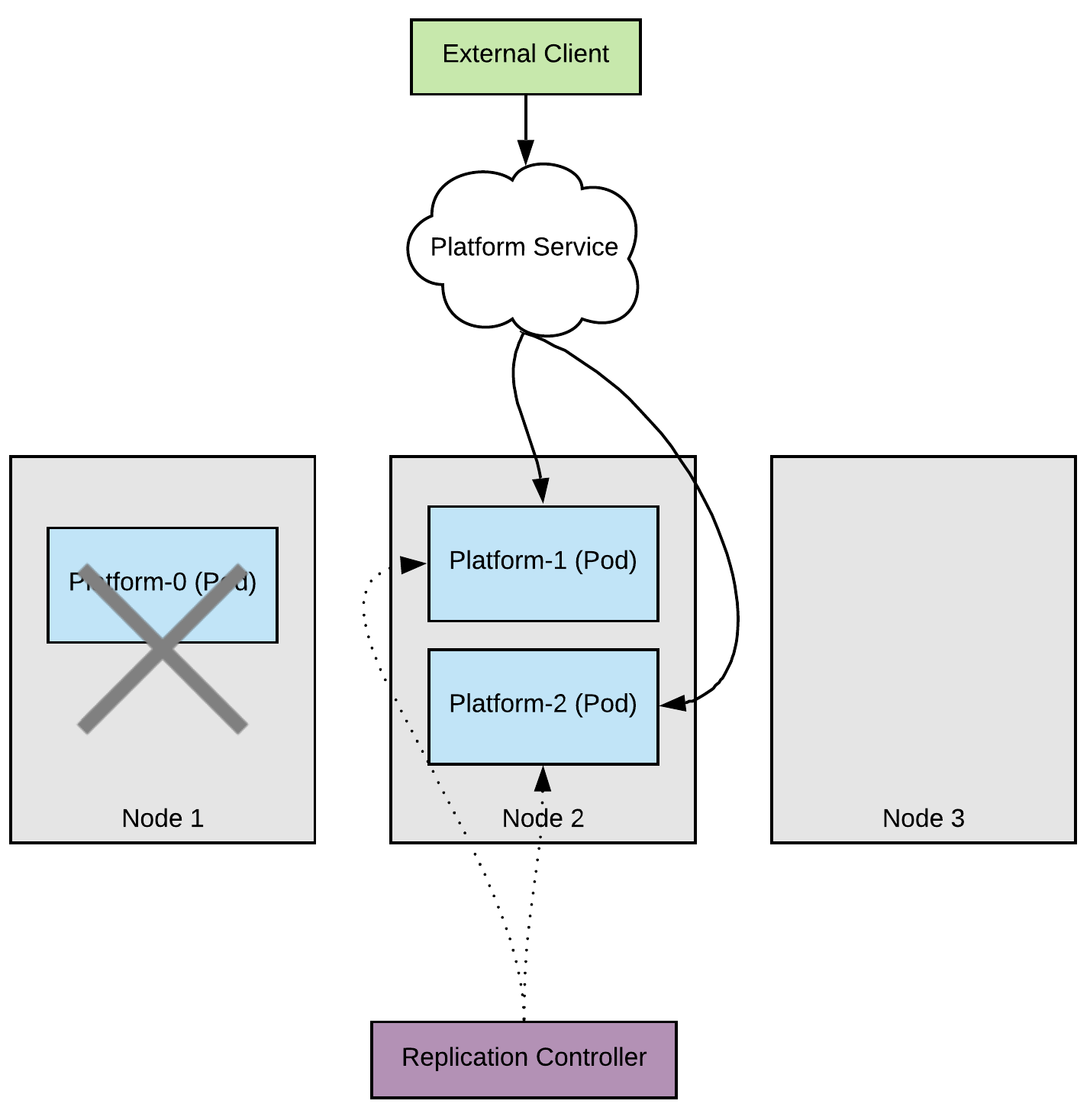
Once again the pod is rescheduled to run on a different node; in this case let’s assume it’s node 3.
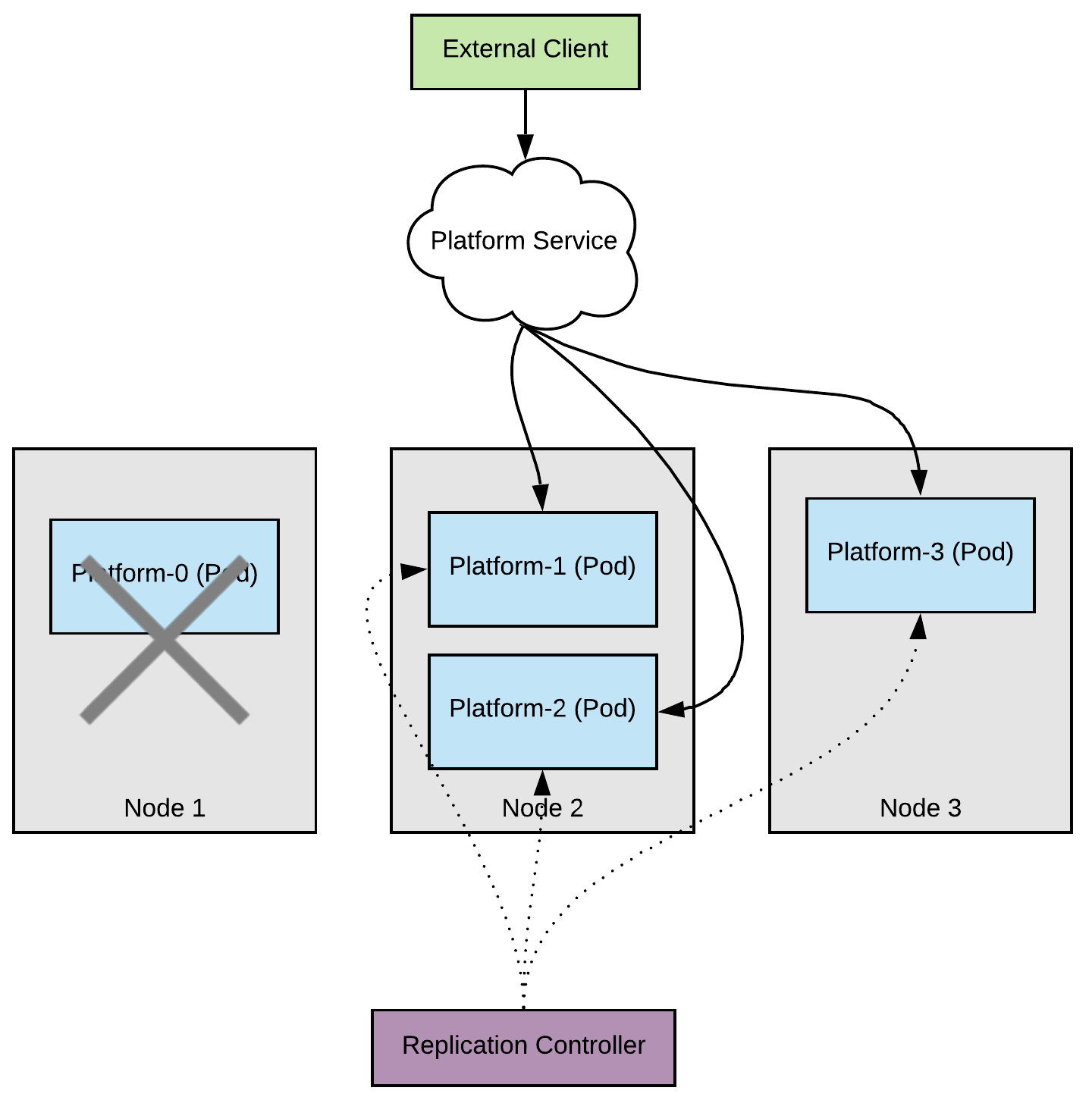
When we upgrade node 2, we end up in a situation where we lose 2/3 of our serving capacity. The clients are still being served by the pod on node 3 but under high load this situation might be uncomfortable.
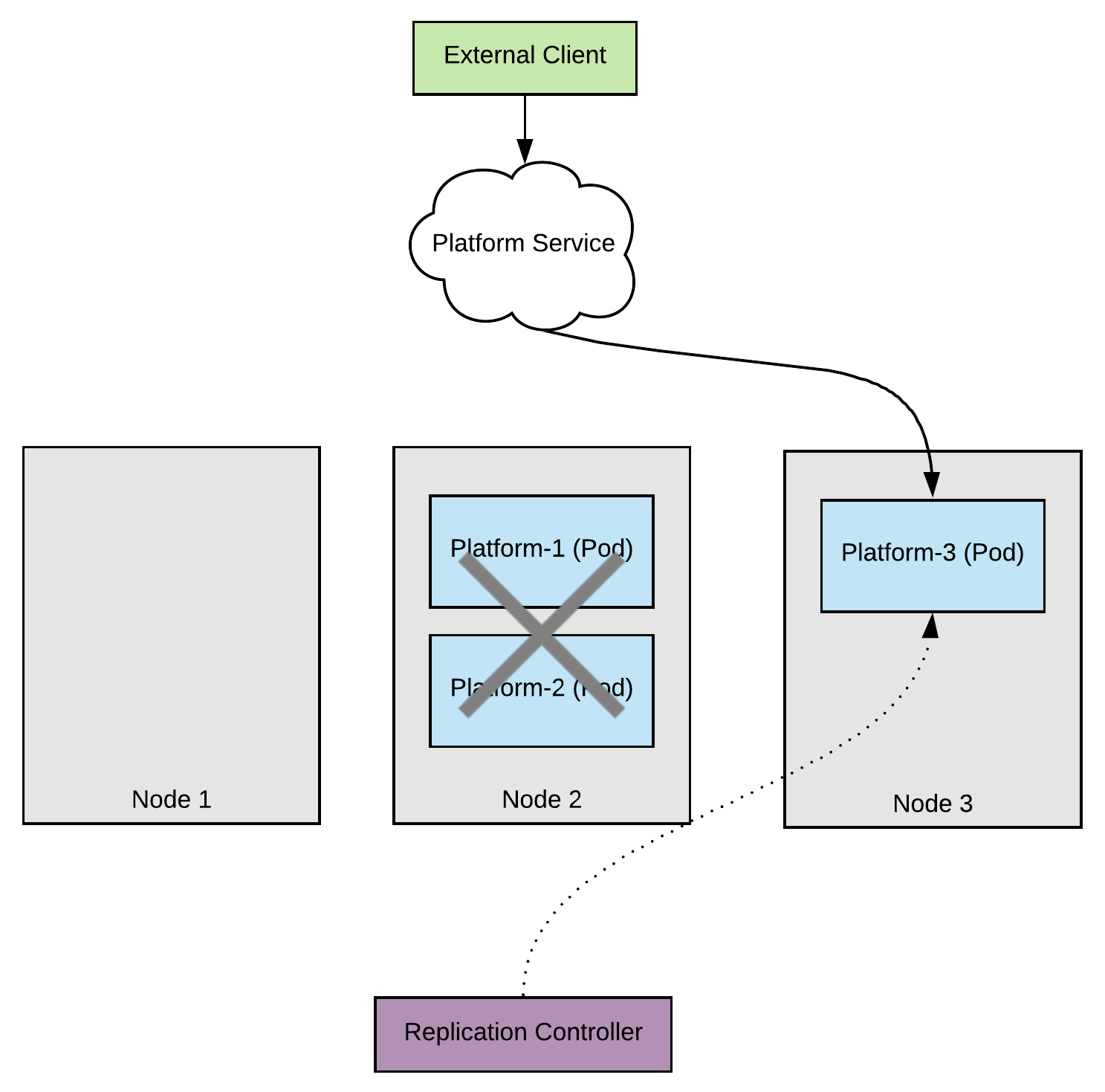
Once again, the two pods are rescheduled by Kubernetes and this situations recovers.
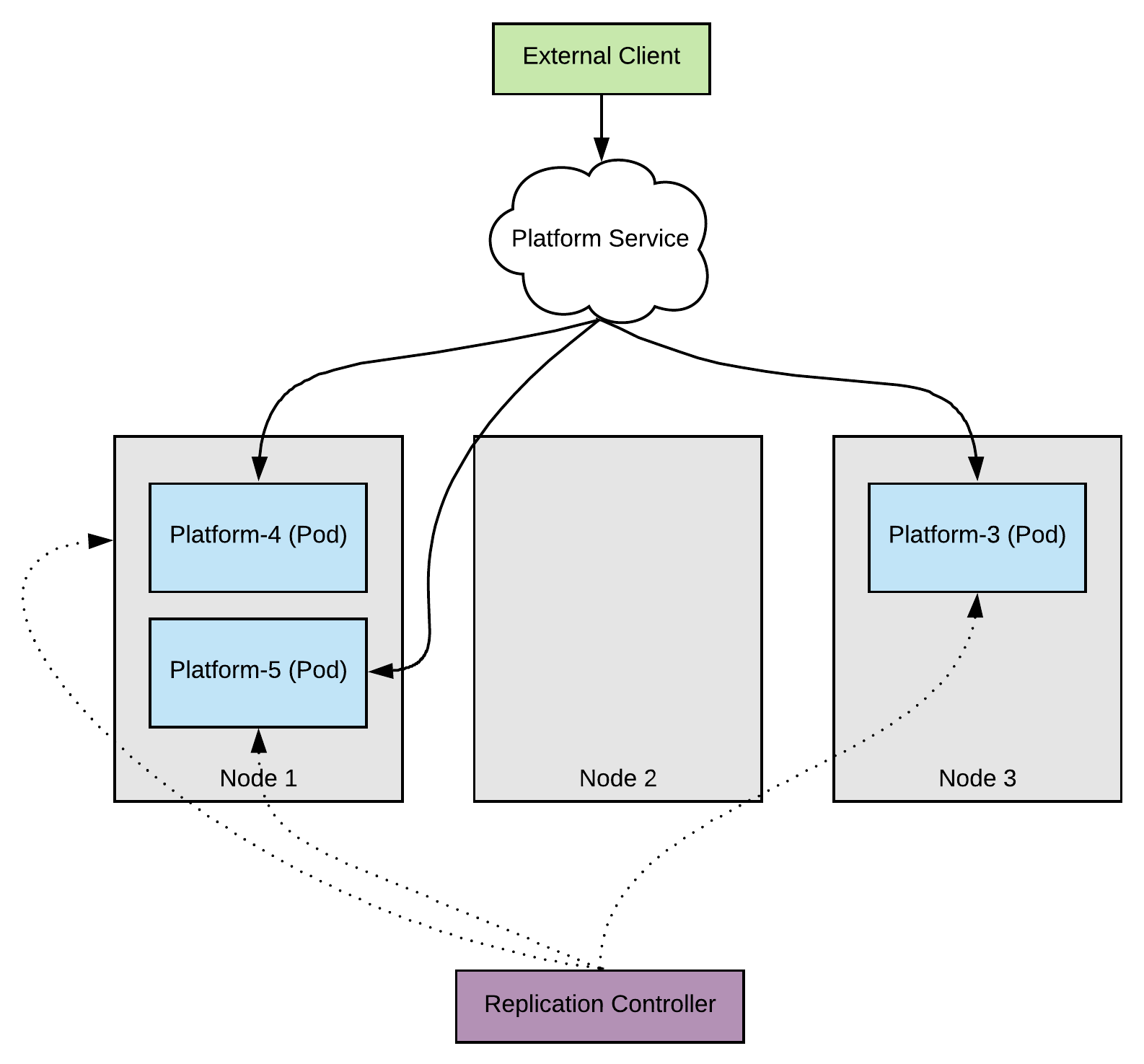
This is clearly not good enough. So, what can we do further?
Pod anti-affinity rules
What we can do in this case is tell the scheduler “Hey, I know what I’m doing, try to schedule those particular replicas on different nodes”. Which is to say that we plan to use pod anti-affinity.
# File: affinity-patch.yaml
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchLabels:
app: platform
topologyKey: "kubernetes.io/hostname"
> kubectl patch deployment platform --patch "$(cat affinity-patch.yaml)"
Once we update our deployment to use pod anti-affinity the scheduler distributes the pods evenly across the nodes.
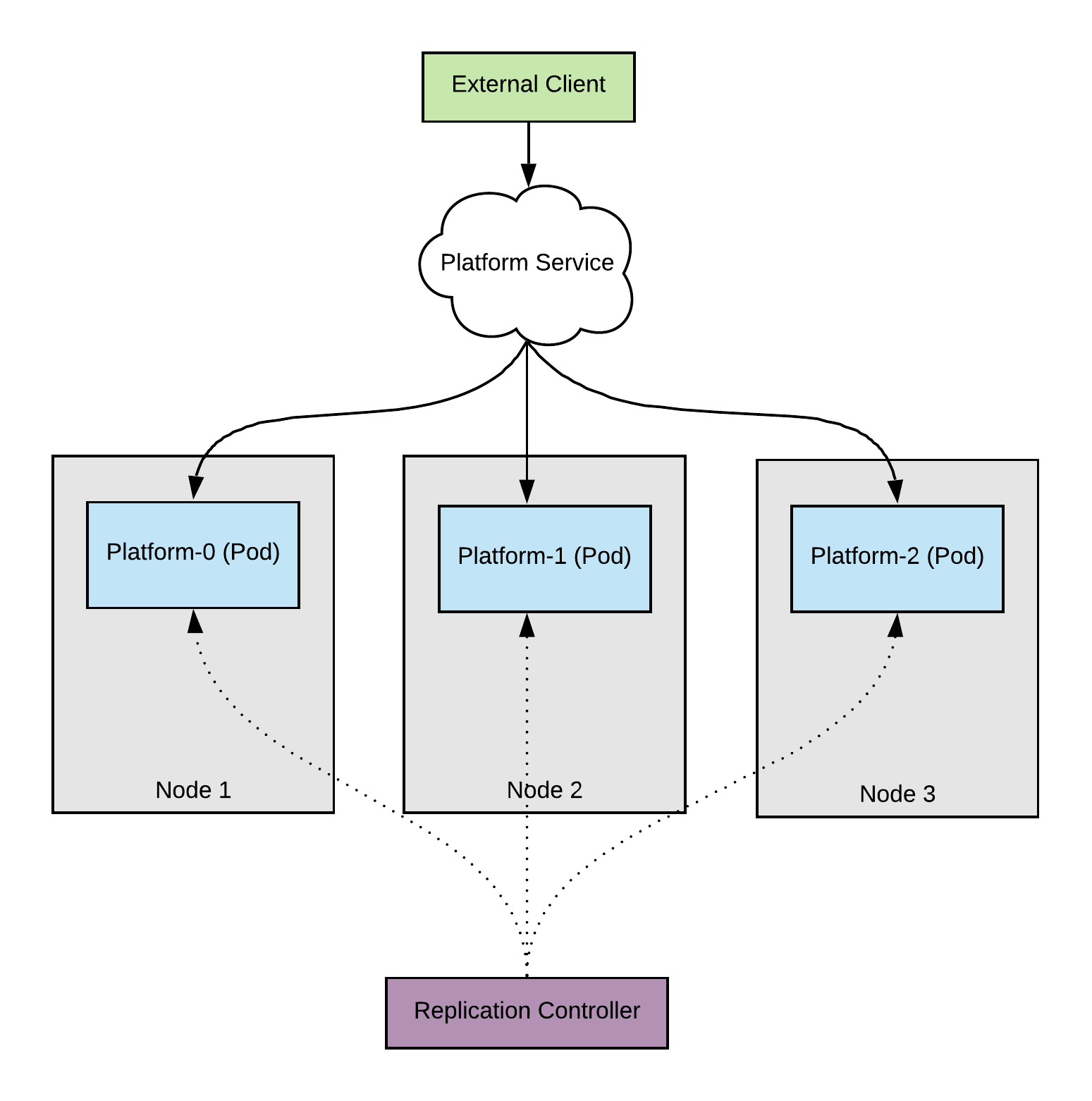
Here, you can rely on the fact that 2/3 of the client capacity will always be available during an upgrade.
Take away #1 - Redundancy
Replicas and Pod Anti-Affinity rules lead us to our first take away - redundancy. There are many things which GKE does (such as surge upgrades) but we have to help ourselves by giving ourselves a little bit of slack. Here we are going to use the simplest formula from SRE - N+1 - which informally translates to “give yourself some breathing room”. Not only that but also use this breathing room as an advantage. You can think of your application as different fault domains that you want to separate and run individually so if part of your application fails the others can survive and serve traffic.
Protection
So, is redundancy enough? Let’s have a look. Ralph (a.k.a Wreck It Ralph since the incident) joined the team and was working on a script.
for node in `kubectl get nodes -o jsonpath='{range.items[*]}{.metadata.name} '`
do
drain="kubectl drain $node --ignore-daemonsets &"
eval $drain
done
As it turns out this script ended up draining the cluster causing a total outage; Ralph cordoned all the nodes and also evicted all the pods.
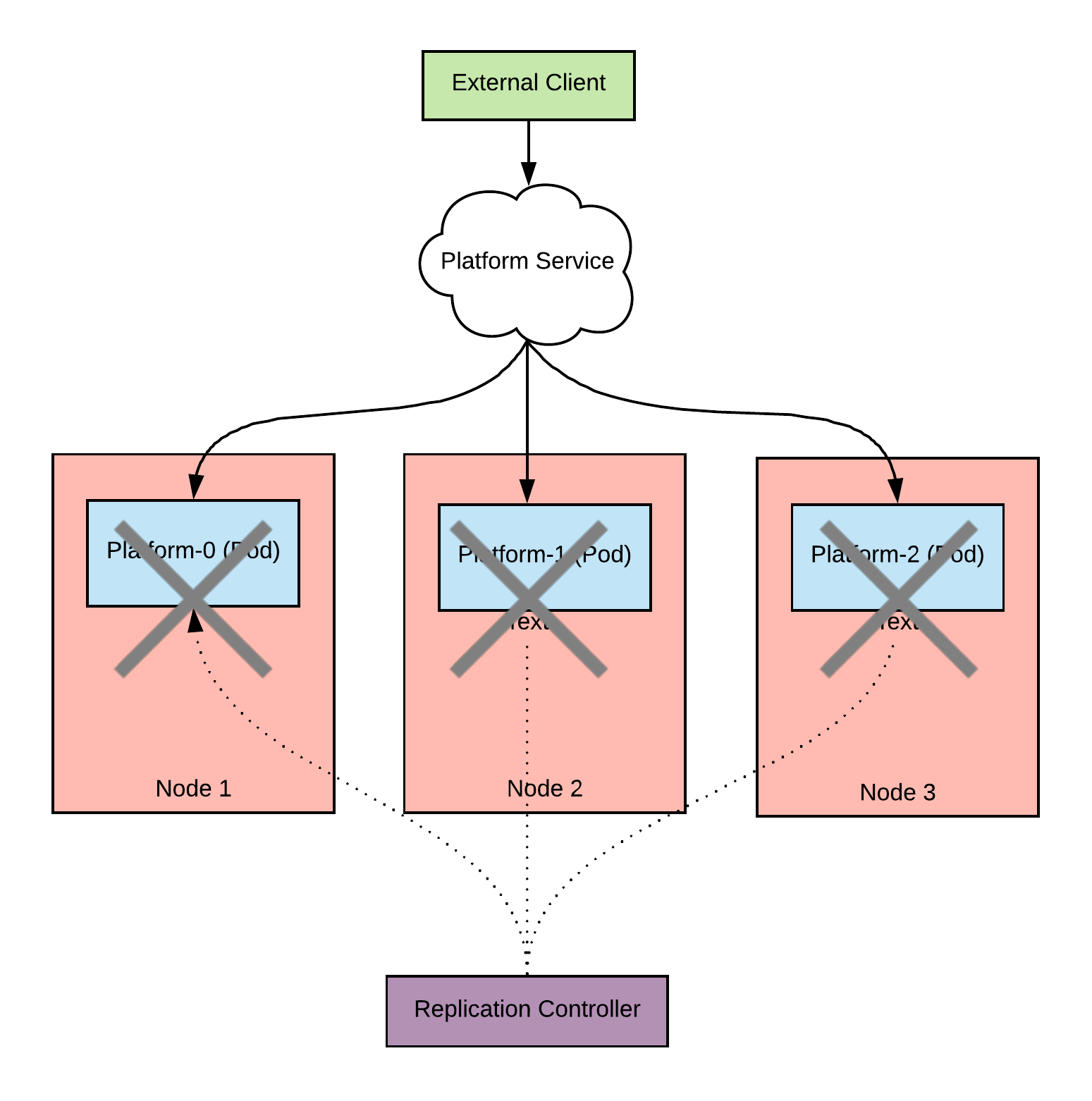
What can we do to protect our pods?
Pod disruption budgets
Here we can see that this is an honest mistake but the key takeaway here is that no amount of redundancy could have saved us.
What can we do to protect ourselves from this situation? Kubernetes is such a huge universe that there are many mechanisms. One simple thing we can do here is to add a pod disruption budget.
# pod-disruption-budget-platform.yaml
apiVersion: policy/v1beta1
kind: PodDisruptionBudget
metadata:
name: platform-pdb
spec:
minAvailable: 2
selector:
matchLabels:
app: platform
> kubectl create -f pod-disruption-budget-platform.yaml
A pod disruption budget is a place where you say to Kubernetes “OK, these are the pods that I want to protect”. In this case the rule we want to apply is the minAvailable. What this means is that at any point in time there should be at least 2 pods available. There are other rules like maxUnavailable, which specifies how many at a time can be unavailable.
If Ralph tries to drain everything again he will get these error messages.
error when evicting pod "platform-68ddf77fc8-44hch" (will retry after 5s):
Cannot evict pod as it would violate the pod's disruption budget.
error when evicting pod "platform-578f5c9499-vrgtq" (will retry after 5s):
Cannot evict pod as it would violate the pod's disruption budget.
The scheduler here is telling us that it cannot evict the pod because it would violate the rules.
Let’s look at the current situation of pods and nodes below.
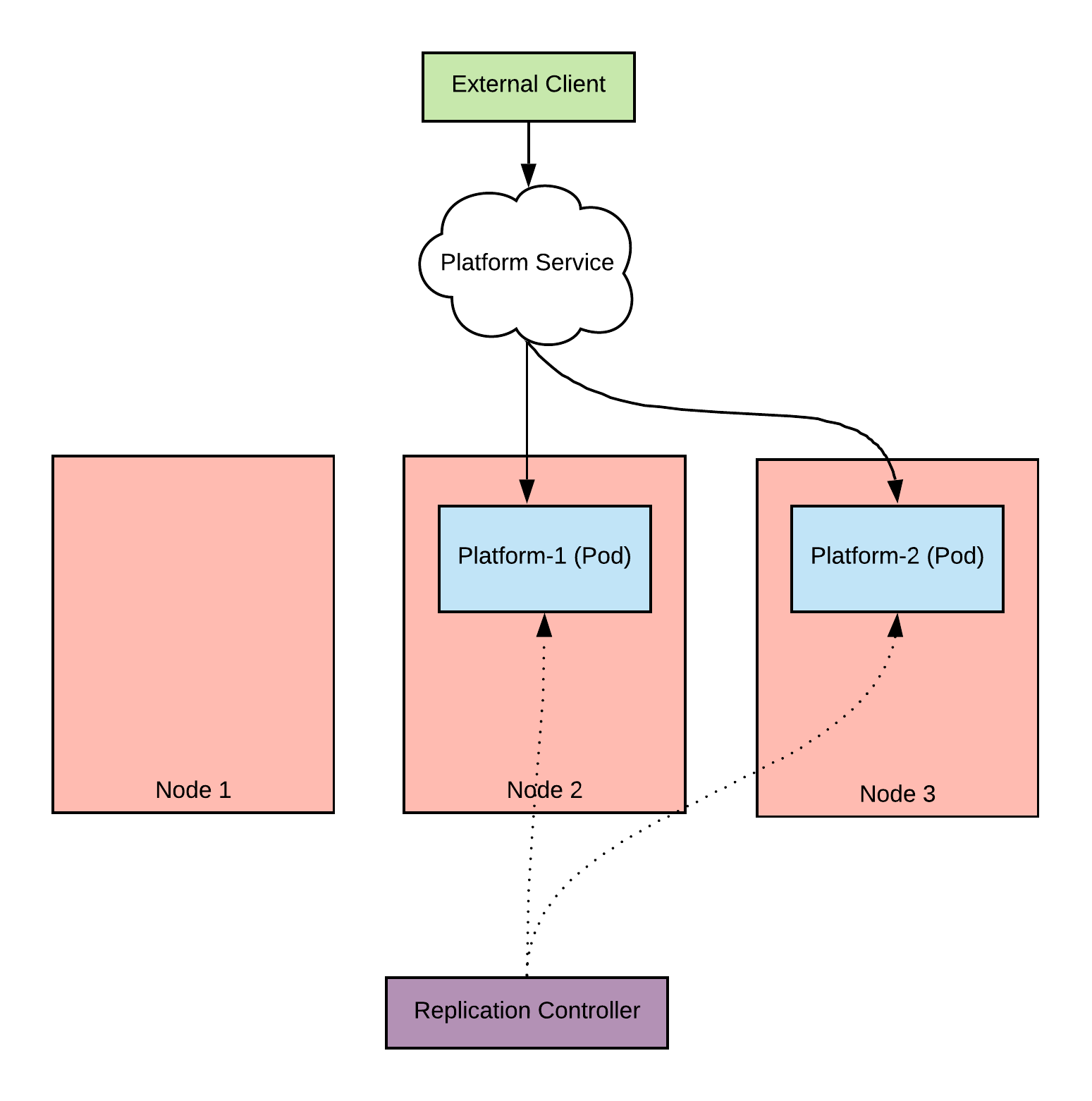
As you can see, we still did some damage here. We got rid of one pod from node 1 and that all nodes have been cordoned but what’s important here is that there is no total outage. We are still serving traffic and we have time to recover.
Take away #2 - Protection
So redundancy is not enough. You have to put some protection if you are extra paranoid and it’s good to be extra paranoid for sensitive resources.
Liveness and Readiness Probes
Kubernetes does not know what an application running inside a pod is doing - it’s a black box. If a pod crashes Kubernetes will automatically restart it but at times applications stop working without their underlying process crashing. For example, out of memory exceptions in Java or wrong application code. Let’s have a look
var requestCount = 0;
var handler = function(request, response) {
console.log("Received request from " + request.connection.remoteAddress);
requestCount++;
if (requestCount > 5) {
response.writeHead(500);
response.end("I'm not well!");
return;
}
response.writeHead(200);
response.end("I’m healthy!);
};
One of our developers accidentally made changes to the handler logic of our application. After 5 request our application will reply with HTTP status code 500. This is clearly not what we wanted. After approximately 15 requests all of our replicas will start reporting 500 errors.
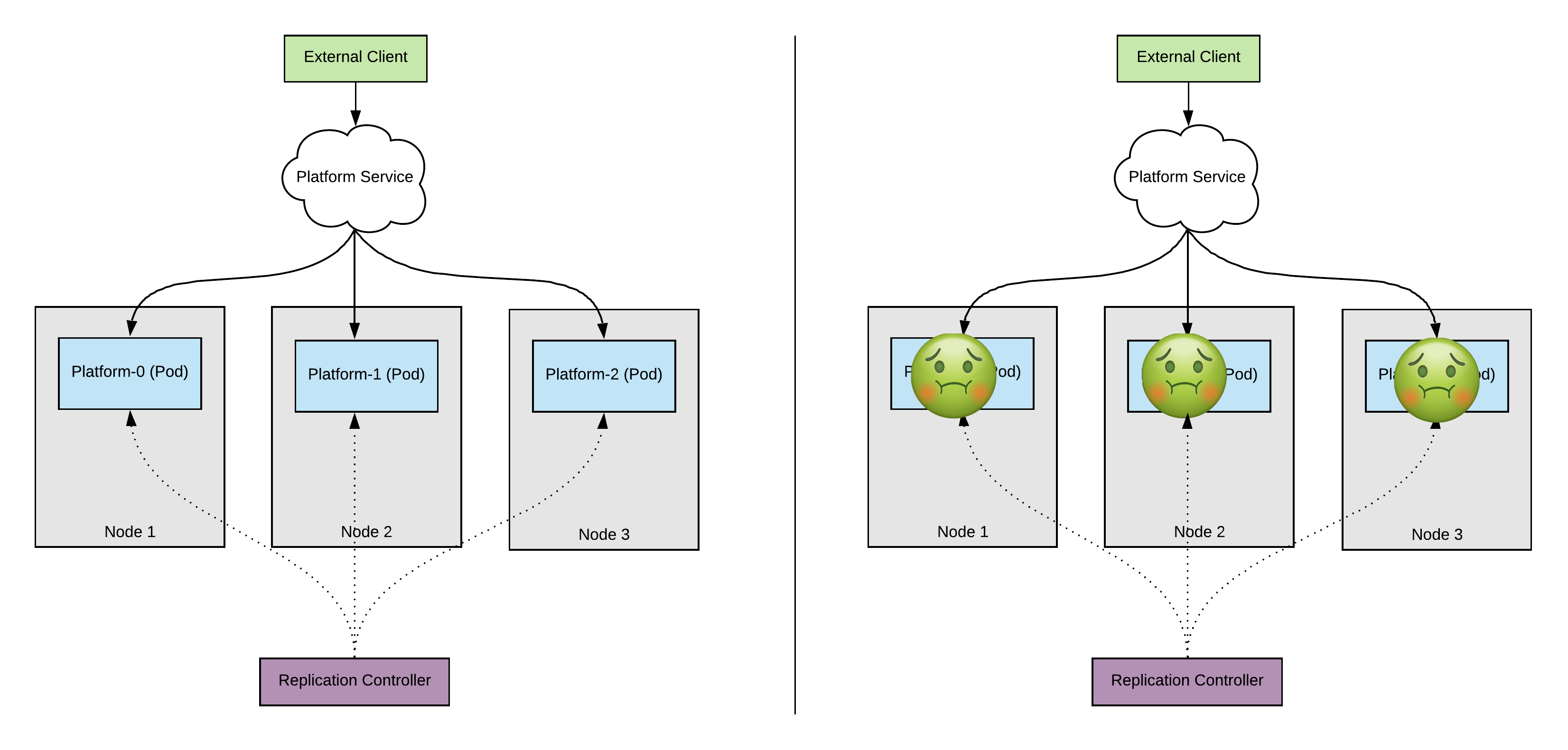
From a Kubernetes point-of-view the application is healthy and no pods are restarted. But we can do better than this. By giving Kubernetes some insight into our pods Kubernetes can help us out. We do this specifically with the readiness and the liveness probe.
-
Liveness probe determines whether your application is healthy enough. If the application is not healthy, Kubernetes will restart the pod.
-
Readiness probe allows Kubernetes to check whether your application is ready to receive traffic but will not restart the pod.
In case of our simple application we will use an HTTP probe to determine whether the application is healthy (liveness)
livenessProbe:
httpGet:
path: /
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
As soon as the pod starts returning errors, the pod will fail the liveness check and will eventually be restarted.
Take away #3 - Insights
So take away number three, help Kubernetes help you by giving Kubernetes insight into when your application is ready and available.
Additional Protection Mechanisms
There are other features in GKE which are worth mentioning.
-
Surge Upgrades First feature, which we already discussed, is surge upgrades. Surge upgrades will really reduce the disruption times by creating an extra VM before draining old nodes.
-
Enhanced Maintenance Windows Google has a feature called auto-upgrades which automatically updates worker nodes. Unfortunately this feature is rarely used since this takes a lot of control from us. As application administrators we want to be fully in control when an upgrade happens since we want to really reduce the impact to our business. Enhanced Maintenance windows allow us to specify that we want to avoid upgrades during inappropriate times such as weekends, Black Friday or Cyber Mondays. Furthermore, enhanced maintenance windows allow us to postpone (snooze) a schedule for a short period of time.
-
Canary Clusters This enables us to create canary clusters and link them to our production clusters. This will indicate to GKE to roll out new versions to the canary cluster first, allowing us to run automated tests. Roll out to production clusters will be conditioned on the results of these tests.
Conclusion
In this blog post we looked at how we can control disruptions during node upgrades. In summary we should really focus on three take aways
- Redundancy - give yourself some slack by adding more replicas and using pod anti-affinity rules
- Protection - put protection mechanisms in place for pods which you want to protect
- Insights - give Kubernetes a bit more insight into your pods via liveness and readiness probes.
There are also some interesting features coming up which you should look out for such as surge upgrades and enhanced maintenance windows which will help us further control disruptions. As always, stay safe, keep hacking.